>>> Click here to access this episode of the Syllab Podcast on Spotify <<<
a) What makes a machine language
In Chapter 1 we saw how data can be manipulated and in Chapter 2 how it can be written, stored and read to or from different kind of media depending on the use case and the need for capacity, speed, accuracy or portability. So, assuming for a moment we are a machine, we have the tools and we can write and retrieve instructions, yet we can only do so if these instructions are conveyed to us in a binary language of 1s and 0s, so we can’t understand what a human is asking us to do in her own language. In this third chapter, we will thus start by exploring what it takes for a language to be understood by machines and how to make programming by humans easier, without having to resort to binary code. We will then explore the steps involved between instructions in a non-machine programming language and its execution by the computer hardware.
In its lowest-level form, machine code is a series of a limited set of instructions interpreted by firmware at the level of each hardware element. These instructions each involve one step such as fetch data from address X in the cache memory or execute arithmetic operation Y. This makes for very limited syntax or language structure and very limited vocabulary as well, which introduces a lot of repeat when programming directly in machine code. Instead, programming languages have developed with a range of degrees of abstraction, from the low-level shown in Figure 2 below that bears many similarities to machine code to the high-level that feels a lot more like human technical language albeit a stilted version arranged in logical sequences. Thus, it is possible to develop programs with a much wider vocabulary as far as the human programmer is concerned and, behind the scenes, many terms refer to a much longer definition or recipe.
Figure 2: Assembly Vs Machine languages
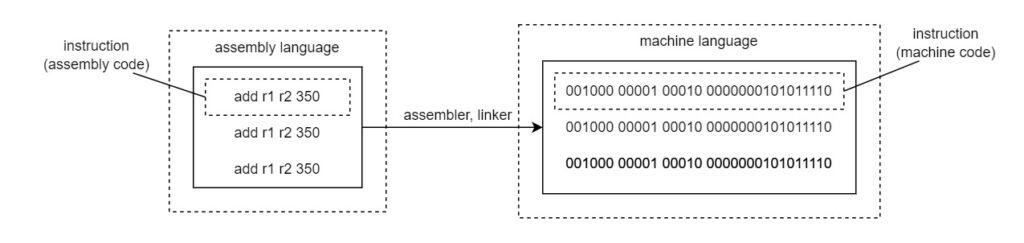
Credit: ShiinaKaze (CC BY-SA 4.0)
Of course, this creates a large gap between the machine and non-machine programming languages and this gap is positively correlated to the degrees of abstraction, and so is the time required for execution. We’ll get to this in the next section but such fact is worth pointing out now because this highlights one of the reasons why there are so many different languages: they fit different use cases. No programming language is perfect, each has its advantages and its drawbacks including ease or difficulty of learning, speed of execution, ability to manipulate large datasets, etc.
Another fundamental difference between machine and human language, and this has to do as much with the language structure as with the data flow and the content of a computer memory, is that machine language is context-free. As a consequence, one needs to be very prescriptive when programming because there is no implied knowledge other than the meaning of the words available in the language being used. If you do not spell it out, and spell it out without making a typo, then the computer will either not understand it or worse, misunderstand it. This is a reason why bugs are often difficult to spot, unless a dedicated program is looking for typical mistakes such as the use of invalid variables; the machine cannot put itself into your shoes and second guess your meaning. In this sense, computer programming is an excellent exercise in learning to express oneself in a clear, comprehensive and logical fashion. Not the recipe for a relaxed dinner between friends though…
b) Compilation, interpretation and execution
So, back to our language gap, how do we bridge the separation between non-machine to machine language? There are two different avenues and a few hybrid options between those: compiling and interpreting. Think of compiling as a translator opening a book written in a non-machine language and rewriting all the content into a new book in machine language. Except, instead of the first book we have a program and instead of the second book we have an executable program; this means the result of the compilation can be reused several times and the compilation can have taken place well before the execution time and quite possibly on a different machine altogether.
Unlike compiling, interpreting is a lot more like having a translator doing his job on the fly, translating then executing instructions in real time. For optimization reasons, the interpreting of high-level languages may involve translating into an intermediate language (lower-level than the source code) and execute this or re-arrange the source code into a data structure that can be more efficiently executed, this is called parsing.
Since the beginning of this chapter the word “execution” has been referred to a few times, there is nothing mysterious about this and, like we saw in S4 Section 2.b, it consists in the control unit going through each set of instructions in the program, whether in its direct, interpreted or compiled version, and each instruction generally calls for a fetch-execute or a fetch-decode-execute cycle. Nowadays, whenever possible, the instruction pipeline will let CPUs execute several instruction cycles concurrently, provided of course there are not dependencies, in which case those are carried out sequentially. If you wish to read more about program execution and execution time, also known as runtime, I have included a link to the Wikipedia entry in the last section of this chapter. This is followed by a link to the entry for instruction set architecture.
The concept of instruction set architecture (ISA) captures and regulates the relationship between programs and the CPU, including the acceptable types of data, word length (a word is a unit of data such as 32-bit, which is 4 bytes), and the addressing mode – the latter provides the algorithm to work out the memory address of the operands. Historically, for consumer computers, the x86 instruction set from Intel has dominated the market and is used by AMD chips as well. However, in the last few years, another architecture called RISC (reduced instruction set computer) has met with increasing development and commercial success, spearheaded by ARM, the company that designs chips like the Apple M series and the majority of smartphone chips, mostly on account of its better power efficiency, something which matters for portable devices.
This is problematic for operating systems and applications based on x86, though the progresses in emulation, essentially interpreting programs across instruction sets rather than just into machine language, is proving to be an increasingly viable alternative until different native versions are developed for each ISA.
c) Operating Systems and applications
Since we just mentioned operating systems and applications, what do we mean by that and what purpose do they serve? There is no neat dividing line, nonetheless applications is meant to refer to software developed for end users for purpose others than managing and operating a computer, which is the domain of the operating system. Thus a word processor is an application, so is the media player software on your computer and the messaging app on your smartphone. On mobile devices more so than on desktops, the downloading of these apps is often restricted for security and financial reasons to a channel controlled by the hardware manufacturer or the operating system developer; these are colloquially called app marketplace or app store.
On the other hand, the operating system (OS) interfaces between these user-software and the computer hardware (including by way of firmware). It consists of some administration systems, potentially some other bundled functionalities such as a file explorer application providing a visual abstraction of the mass storage available on or to the computer, and the kernel. The kernel is the always-on layer which provides security, interacts with input and output devices (“I/O devices”), and manages hardware resources such as the allocation of memory and processing capacity when several applications are running concurrently. Undoubtedly the biggest job in town for your computer. Part of this management includes interrupting and resuming a particular program, which necessitates informing the CPU and saving the state and values of the process, not providing access to data and other resources unless proper authentication has occurred, and preventing the intrusion and spread of malware (malicious programs intended to steal data or cause other harm to the computer).
Considering the number of capabilities involved and the ecosystem of applications developed and compiled for a particular OS, it isn’t that surprising the number of commercially successful ones can be counted on two or three fingers for each form factor of an electronic device. For desktop computers, these are Windows, macOS and Linux, the latter being open-source with a significant range of variations called distributions such as Ubuntu and Debian (at the time of writing), and it is also the dominant kernel for servers and supercomputers.
The most widely used OS nowadays isn’t Windows though, the rise of smartphone penetration and the fact the platform is not exclusivity tied to a single hardware manufacturer means it is Android, which happens to be Linux-based. The other alternative to classic operating systems installed on the device is Chrome OS or Chromium OS, they are designed to browse the web and run web applications, and they are also a Linux distribution!
d) User Interfacing and app architecture
When discussing abstractions in programming language, it was mentioned this made it easier for developers to code because higher-level languages are more intuitive. The same abstraction plays out in the way we, lambda users, interface with our computers. We take all those icons on a screen, nicely laid out in windows or tabs, for granted but it was not always like this and originally the interaction was mediated through a command-line interface (CLI). It is still very much there as part of your operating system, if you have Windows use the Winkey then type “cmd” and press enter, on macOS the Terminal app gives you access to the same capabilities. Generally, you would only use this interface to manage the computer infrastructure via utility software or perhaps for administration.
Instead of CLI, applications and OS offer the user a graphical user interface (GUI). This works two ways: the user provides an input, this is taken into account by the application which refreshes the output, most likely in a visual form. On personal computers, the most widely-used GUI elements are windows, menus, a pointer, text fields and icons. With the rise of mobile devices, this is however not a static set and new modes of interactions are being devised to make user experience better given the constraints in terms of pixel real estate.
The notion of user experience, colloquially shortened as UX, is nowadays central to the development of applications and is a key reason why native applications have an edge over web apps when used on a narrow mobile screen. Indeed, the flow and navigation can be engineered to create less friction, for example splitting inputs over several pages instead of having all of them on a single page. The pendant of UX in terms of design is UI, which stands for user interface and is mostly concerned with the look and feel of the content being displayed, including the choice of fonts and colours, layout and graphical elements as well as the considerations relating to accessibility so that users with certain disabilities may still be able to use the application.
The screen is arguably the most important interface and primarily acts as an output device, but it is far from the only one. The other key I/O devices include the keypad for text, the mouse to move the pointer on your screen, the touchscreens (especially on mobile devices) and perhaps the stylus. All of these are actually input devices and for output, besides monitor screens (we will look at screen technology more in depth in S4 Section 8.e), the most ubiquitous are soundcards and printers.
- Keypads for computers would have numeric and alphabetical symbols as well as several function keys that can be hardwired or programmed. Combinations or “shortcuts” can also be programmed in the operating system to virtually extend the number of keys. The two dominant technologies are membrane and metal switches. The former type has a top and bottom layer with electrical wiring and an isolating layer in between which allows the current to pass when the top layer is pressed down sufficiently. The latter has individual keys transferring vertical pressure to a pair of switches coming in contact and thus conducting current with a spring to bring the key back up to its default position – these are colloquially called mechanical keyboards.
- A computer mouse translates the movement of our hand into the movement of a pointer on a screen and, for convenience, one or several buttons can be added as well as a scrolling mechanism. The original mouses were mechanical and used a ball and rollers mechanism: one roller to detect movements along a vertical axis (on a 2-D horizontal plane), one for left-right and a third one to keep the ball in place, applying pressure towards the other two rollers. The turning of the rollers would be transferred to rotating discs with holes at regular intervals that would interrupt or let through infrared light beams (a pair of them per roller to be precise) and so a light sensor would transfer this information as electrical pulses with some asymmetry built in the encoding holes to infer the direction of travel (left Vs right and front Vs back which is translated as up Vs down on a screen). Modern mouses no longer have a rubber ball and instead rely on the optical detection of movements relative to the surface via infrared laser. You probably do not realize it but the way it detects movement is essentially by casting shadows on the irregularities of a surface and comparing the relative change in position of those physical features over time. This explains why the technology works best on opaque surfaces with diffuse reflection rather than on transparent or polished surfaces like glass or a marble tabletop.
- Touchscreens merge visual displays with tactile or stylus inputs. They come with different properties, advantages and drawbacks depending on the technology being used. For example resistive touchscreens are analogous to membrane keyboards and the pressure applied allows the current to be conducted in one location – but this works only for one spot at a time so multi-touch cannot be supported. Capacitive touchscreens do not rely on mechanical pressure and instead leverage the fact that human skin conducts electricity so contact will disturb the screen’s electrostatic field, which can be detected. This technology will not work when the fingers are covered with non-conducting materials such as glove though. Infrared touchscreens use a pattern of laser beams and triangulate where the beams have been interrupted, or so they think, hence the accidental press when your finger is hovering close to the surface. Muti-touch sensing and the ability to detect rotation is also limited. There are a few other technologies and this is clearly an evolving market.
- Fingers are not the only way to convey information to a screen and styluses offer additional functionalities and increased accuracy. Like a finger, a stylus can be used on resistive touchscreens or on capacitive touchscreens if it contains conductive material; in either case the device itself offers no incremental benefit and does not need to be powered. Not so with powered styluses containing digital components called active pens. These can communicate other variables such as pressure intensity (detected by built-in sensors) or the clicking of programmable buttons to the multi-touch device.
- A sound card, also called audio card, can be used both to process inputs (think microphone) and outputs (think speakers or headphones). The mechanical aspects of transducing sound waves into electrical signal, and vice versa, would be part of the device interfacing with the end user and the card is in charge of converting analog signals into digital ones, or the opposite.
- Finally, document printers (so not 3-D printers) are dominated by inkjet and laser technologies. Inkjet relies on the targeted spraying of microscopic droplets of coloured ink on a paper or plastic substrate. Fortunately, colour mixes can be created by juxtaposing or blending inks in the three primary colours of cyan, magenta and yellow though for black a dedicated ink is required. This follows the CYMK colour model and, to create white, either another ink is necessary or no ink is used and hopefully your substrate is white in colour. If you are puzzled which are the primary colours: CMY or RGB, the answer is both, or it depends. RGB works when light is emitted and CMY when it is reflected: cyan absorbs red, magenta absorbs green wavelength and yellow the blue ones while the key (generally black) is used to absorb all wavelengths. RGB is said to be additive and CMY subtractive. As for laser printing it works on an entirely different basis and is best used for text and graphics rather than photographs. There are three steps involved, #1 the creating of an electrostatic “master” by beaming a laser on a cylinder, and #2 the transfer of ink attracted to the areas with the pronounced electrical charge. This happens for each of the 4 coloured inks in the colour printer version, typically the same CMYK as for inkjet. #3 the final step consists in heating the result so the ink and substrate can fuse. Of course, this is significantly oversimplified so if you want to give the technology its intellectual due you can follow the link to the Wikipedia entry for laser printing included at the end of this chapter or alternatively you may want to look for a video explanation.
e) Frontend, API and backend
This requirement for representing information in a manner that can be sensed and acted upon by human users, as opposed to machines, means an application needs not only carry out the core of its service behind the scenes but it needs to be complemented by a user-friendly interface. The latter is known as the frontend whereas the heavy computing involving the logic and data manipulation, including access to and administration of databases, belong to the realm of the backend.
This dichotomy creates some additional work of course but also allows for a physical separation: the frontend needs to occur in front of the client, hence it is called the client-side, whereas the backend can potentially be located elsewhere, on the server-side. When you run a program directly on your computer there is no physical separation but every time you use an online application this is what happens, the core of the processing happens in a server farm and the data is passed to and fro between the front and backends via APIs.
API stands for application programming interface and can be thought of as a standard template for communicating streams of data. Some APIs can be standardized or they can be proprietary. Data itself can be distributed to third parties via APIs, either for free or at a price. Maybe you have used some transport apps in cities allowing you to know when a specific bus service will come up next at a given bus stop; this is made possible by the operator providing the data from the buses to a program which consolidates the information and makes it available to various apps via its API.
As for servers, they are essentially computers with only a minimum user interface since they are designed to provide computing resources to users located elsewhere. No need to look good and they can be stacked and lined up in rows in data centres.
Because the division between front and back entails a difference in the kind of computing tasks being carried out, this means some programming languages are better for front rather than backend. In fact, it means some languages are developed only for front and others for the backend.
For example, website pages would use JavaScript for data management and interactive behaviour, HTML for text display and content structure and CSS for design and layout. For the backend Python is popular for machine learning, SQL and NoSQL for database queries and manipulation, and C# and Ruby for building webapps with the .Net and Ruby on Rail frameworks respectively.
f) Trivia – Natural Language Processing
In section a) I highlighted some of the fundamental differences between human and machine languages, which forces us to use rigidly structured syntax, fully prescriptive content and value declaration, and a restricted number of words with enshrined black-and-white semantic. How come we are increasingly able to talk to machines then and how can they recognize written characters and even make sense of them?
This has to do with natural language processing, the scientific domain seeking to automatically interpret human language (also known as natural language). This involves a lot of modelling, for syntax in particular, as well as inferences to create what is called knowledge representation in the form of word embedding. This representation doesn’t capture truth value nor does it form a database of knowledge; rather it relies on correlation and more broadly patterns observed over trillions of tokens (bits of information) to which complex layered algorithms are applied in the case of large language models (LLMs). To better understand the natural and artificial techniques for concept embedding you may want to read Chapters 4 and 14 of my book, Higher Orders.
Not only are the latest LLMs able to understand natural language but they are also able to generate content, what we call generative AI. And they can do so in a cross-modal way, ingesting written content, processing it and outputting voice or graphical representations for example.
g) Further reading (S4C3)
Suggested reads:
- Higher Orders, by Sylvain Labattu
- Wikipedia on Instruction Set Architecture: https://en.wikipedia.org/wiki/Instruction_set_architecture
- Wikipedia on Execution in computing: https://en.wikipedia.org/wiki/Execution_(computing)
- Wikipedia on Laser printing: https://en.wikipedia.org/wiki/Laser_printing
Disclaimer: the links to books are Amazon Affiliate links so if you click and then purchase one of them, this makes no difference to you but I will earn a small commission from Amazon. Thank you in advance.
Previous Chapter: Digital data storage
Next Chapter: Wired Telecommunications